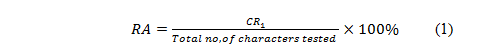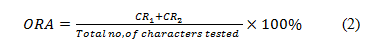 IJCRR
IJCRR International Journal of Current Research and Review
Welcome to IJCRR
Indexed and Abstracted in: Crossref, CAS Abstracts, Publons, Google Scholar, Open J-Gate, ROAD, Indian Citation Index (ICI), ResearchGATE, Ulrich's Periodicals Directory, WorldCat (World's largest network of library content and services)
|
Feature extraction |
% Recognition accuracy |
||
|
k-NN |
SVM |
k-NN+SVM |
|
|
Cell-wise pixel count |
82.3 |
88.4 |
90.8 |
|
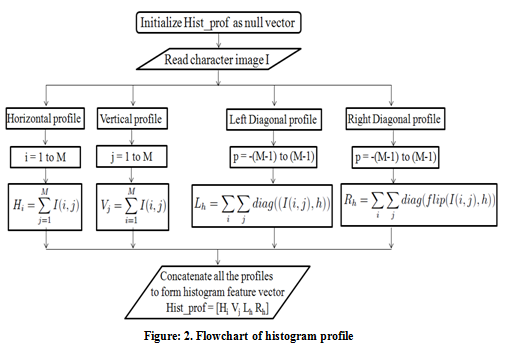
Histogram profile |
73.5 |
77.9 |
79.3 |
It is evident from Table 1 that with the framework of two stage classification, there is a significant improvement in recognition rates. With the two stage classification framework, the cell-based approach gave a quantum improvement in recognizing the handwritten Telugu characters, compared to the Histogram profile-based approach. An improvement of 4-5% in recognition accuracy is obtained using the two-stage framework with both the feature extraction approaches.
CONCLUSION
There is no standard dataset for Indian scripts to conduct experiments for handwritten character recognition. Hence, in this work a dataset containing 18,000 handwritten Telugu isolated basic characters is developed. The various feature extraction algorithms employed for character recognition are cell-wise pixel count and histogram profile. The performance of these feature sets are tested with the proposed two-stage classification system.
An improvement of 3-5% in recognition rate is achieved with the proposed two-stage classification system when compared to single-stage classification for the feature extraction approaches considered. The best recognition accuracy obtained using the proposed two stage classification framework is 90.8% with 'cell-wise pixel count' feature set.
ACKNOWLEDGEMENT
Authors acknowledge the immense help received from the scholars whose articles are cited and included in references of this manuscript. The authors are also grateful to authors / editors / publishers of all those articles, journals and books from where the literature for this article has been reviewed and discussed.
References:
[1] M. Cheriet, M. E. Yacoubi, H. Fujisawa, and D. Lopresti, "Handwritten recognition research: twenty years of achievement... and beyond," Pattern Recognition, vol. 42, no. 12, pp. 3131 - 3135, 2009.
[2] A. Amin, "Off line Arabic character recognition: a survey," Proceedings of the Fourth International Conference on Document Analysis and Recognition, vol. 2, pp. 596-599, 1997.
[3] M. S. Khorsheed, "Off-line Arabic character recognition-a review," Pattern analysis & applications, vol. 5, no. 1, pp. 31-45, 2002.
[4] T.-H. Su, T.-W. Zhang, D.-J. Guan, and H.-J. Huang, "Off-line recognition of realistic Chinese handwriting using segmentation-free strategy," Pattern Recognition, vol. 42, no. 1, pp. 167-182, 2009.
[5] P.-K. Wong and C. Chan, "Off-line handwritten Chinese character recognition as a compound Bayes decision problem," IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 20, no. 9, pp. 1016-1023, 1998.
[6] R. Jayadevan, S. R. Kolhe, P. M. Patil, and U. Pal, "Offline recognition of Devanagari script: A survey," IEEE Transactions on Systems, Man, and Cybernetics, Part C: Applications and Reviews, vol. 41, no. 6, pp. 782-796, 2011.
[7] B. Chaudhuri, U. Pal, and M. Mitra, "Automatic recognition of printed Oriya script," Sadhana, vol. 27, no. 1, pp. 23-34, 2002.
[8] S. Antani and L. Agnihotri, "Gujarati character recognition," Proceedings of the Fifth International Conference on Document Analysis and Recognition (ICDAR), pp. 418-421, 1999.
[9] P. P. Kumar, C. Bhagvati, A. Negi, A. Agarwal, and B. L. Deekshatulu, "Towards improving the accuracy of Telugu OCR systems," International Conference on Document Analysis and Recognition (ICDAR), pp. 910-914, 2011.
[10] B. Chaudhuri and U. Pal, "A complete printed Bangla OCR system," Pattern recognition, vol. 31, no. 5, pp. 531-549, 1998.
[11] L. M. Lorigo and V. Govindaraju, "Offline Arabic handwriting recognition: a survey," IEEE Transactions on Pattern Analysis & Machine Intelligence, vol. 28, no. 5, pp. 712-724, 2006.
[12] N. Arica and F. T. Yarman-Vural, "An overview of character recognition focused on off-line handwriting," IEEE Transactions on Systems, Man, and Cybernetics, Part C: Applications and Reviews, vol. 31, no. 2, pp. 216-333, 2001.
[13] G. Nagy, "Chinese character recognition: a twenty-five-year retrospective," 9th International Conference on Pattern Recognition, pp. 163-167, 1988.
[14] U. Pal and BB. Chaudhuri, "Indian script character recognition: a survey," Pattern Recognition, vol. 37, no. 9, pp. 1887-1899, 2004.
[15] T.R.Vijaya Lakshmi, P.N. Sastry and T.V.Rajinikanth, "A novel 3D approach to recognize Telugu palm leaf text," International Journal of Engg. Science and Technology, vol. 20, no.1, pp. 143-150, 2017.
[16] P.N. Sastry, T.R. Vijaya Lakshmi, K. Rama Krishnan and N. V. K. Rao, "Modeling of palm leaf character recognition system using transform based techniques," Pattern Recognition Letters, vol. 84, pp. 29-34, 2016.
[17] P. N. Sastry, T.R. Vijaya Lakshmi, N.V. Koteswara Rao, Krishnan Rama Krishnan, 2017, "A 3D Approach for Palm Leaf Character Recognition Using Histogram Computation and Distance Profile Features,"Proceedings of the 5th International Conference on Frontiers in Intelligent Computing: Theory and Applications, Advances in Intelligent Systems and Computing, Odisha, pp. 387-395, Sept. 16-17, 2017.
[18] T.R. Vijaya Lakshmi, P.N. Sastry, and T.V. Rajinikanth, "Hybrid approach for Telugu handwritten character recognition using k-NN and SVM classifiers," International Review on Computers and Software, vol. 10, no. 9, pp. 923-929, 2015.
[19] T.R.Vijaya Lakshmi, P.Narahari Sastry, and T.V.Rajinikanth, "Feature optimization to recognize Telugu handwritten characters by implementing DE and PSO techniques," Proceedings of the 5th International Conference on Frontiers in Intelligent Computing: Theory and Applications, Advances in Intelligent Systems and Computing, Odisha, pp. 397-405, Sept. 16-17, 2017.
[20] P. N. Sastry, T.R. Vijaya Lakshmi, N. V. K. Rao, T.V. Rajinikanth and A. Wahab, "Telugu Handwritten Character Recognition Using Zoning Features," International Conference on IT Convergence and Security (ICITCS), Beijing, pp. 1-4, 2014.
[21] S. Bag, G. Harit, and P. Bhowmick, "Recognition of Bangla compound characters using structural decomposition," Pattern Recognition, vol. 47, no. 3, pp. 1187-1201, 2014.
[22] Ramappa, Mamatha Hosahalli, Sucharitha Srirangaprasad, and Srikantamurthy Krishnamurthy, "An approach based on feature fusion for the recognition of isolated handwritten Kannada numerals,"
International Conference on Circuits Power and Computing Technologies, pp. 1496-1502, 2014.
[23] U. Bhattacharya and B. B. Chaudhuri, "Handwritten Numeral Databases of Indian Scripts and Multistage Recognition of Mixed Numerals," IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 31, no. 3, pp. 444-457, 2009.
Indexed and Abstracted in






Antiplagiarism Policy: IJCRR strongly condemn and discourage practice of plagiarism. All received manuscripts have to pass through "Plagiarism Detection Software" test before forwarding for peer review. We consider "Plagiarism is a crime"
IJCRR Code of Conduct: To achieve a high standard of publication, we adopt Good Publishing Practices (updated in 2022) which are inspired by guidelines provided by Committee on Publication Ethics (COPE), Open Access Scholarly Publishers Association (OASPA) and International Committee of Medical Journal Editors (ICMJE)
Disclaimer: International Journal of Current Research and Review (IJCRR) provides platform for researchers to publish and discuss their original research and review work. IJCRR can not be held responsible for views, opinions and written statements of researchers published in this journal.
International Journal of Current Research and Review (IJCRR) provides platform for researchers to publish and discuss their original research and review work. IJCRR can not be held responsible for views, opinions and written statements of researchers published in this journal
148, IMSR Building, Ayurvedic Layout,
Near NIT Complex, Sakkardara,
Nagpur-24, Maharashtra State, India
editor@ijcrr.com
editor.ijcrr@gmail.com
 This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License
This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License
Copyright © 2024 IJCRR. Specialized online journals by ubijournal .Website by Ubitech solutions